So far, all my data processing pipelines required manual intervention or were tied together with batch/shell scripts. In most cases, I had to copy batch scripts to the folder where they had to process data, and manually modify paths in Python scripts before running them from Visual Studio Code.This was finally getting annoying enough to consider an orchestration software for running the various tasks in a pipeline, with a web interface for starting runs and checking their status.
There’s quite a lot of choice when it comes to orchestrating software. Some run on specific cloud services like Azure. Others are equally suited to running them on your own systems. The one that got mentioned a lot is Dagster. Everything is defined in Python code and the main concepts are straightforward. Another recommendation was Prefect. I did a bit of testing with it and the terminology is in my opinion a bit more obvious than Dagster’s, but the web UI appears as an afterthought with very limited functionality.
One of the biggest names is Apache Airflow, but it is also often cited as a reason to try something else. I took a look at the documentation and it can most probably do everything that I want it to do, but it also looks a lot more complicated than Dagster, starting with the installation. So Dagster it was.
Installation, first steps, and core concepts
The installation is straightforward, as explained here. I deviated a bit from the recommendations by installing everything through pip, including the create-dagster package. After that you can create a project as described here. Run dg dev inside the project directory to launch the Dagster server and get access to the web UI.
Dagster uses assets, which in my opinion can be considered the individual tasks or processes in a pipeline.Executing them is called Materializing. Resources are things like databases and storage buckets. Jobs can be defined to run several assets.
Defining assets
Assets are defined as Python functions with the @dg.asset decorator.
@dg.asset
def write_config():
do_something...
In a pipeline, it is likely that every asset but the first depends upon an earlier asset. This is represented in the code by the deps parameter:
@dg.asset(deps=['write_config'])
def convert():
do_something
If your project contains multiple pipelines/workflows, it makes sense to assign groups to assets to organize them. You can also have multiple asset.py files by putting them into subfolders, as described here. In a machine learning project, you’ll probably want to split training and inference.
@dg.asset(deps=['generate_yolo_data'],group_name='training')
def train():
do_training

It is possible to have the code that gets executed directly in the asset.py file, but that’s in my opinion a poor choice for both readability and maintainability. I would recommend to keep the actual implementation in separate files and import them.
Adding checks
A feature that I really like about Dagster are asset checks. There’s usually no point in continuing in a pipeline if a task failed or did not produce the desired output. With asset checks, you can implement test that check whether an asset has done what it is supposed to do. The default behavior is to continue anyways, but by setting blocking=True, the run will be interrupted if a check fails.
@dg.asset_check(asset='convert',blocking=True)
def check_conversion() -> dg.AssetCheckResult:
do_check
if check_ok=Trie:
return dg.AssetCheckResult(passed=True, metadata={"message": "Check passed"})
else:
return dg.AssetCheckResult(passed=False, metadata={"message": "Check failed"})
Defining jobs
Jobs can contain all assets in a pipeline or just a few of them. This way it is possible to configure variants of a pipeline – one might require the download of the data, whereas another will operate on data that is already downloaded. The job definition for a job that uses three assets might look like this:
copy_prepare_train_job = dg.define_asset_job(name='copy_prepare_train_job',selection=['copy_labels','generate_yolo_data','train'])
Runtime configuration
Runtime parameters can be configured in an instance of the dg.Config class:
class MyAssetConfig(dg.Config):
input_folder : str = r"c:\work"
hull_file: str = 'hull.gpkg'
Where Dagster is lacking a bit in my opinion is in the configuration of parameters for tasks/assets from the web UI. This is done through the launchpad, which can be accessed both on the Asset and the Job screen. It shows the predefined values for configuration options defined in the code. The annoying thing is that, if you want to change them, you need to do so for each asset individually, even if they all use the same configuration variable. Parameters for checks are not accessible at all, and changes are not persistent, i.e. not stored.
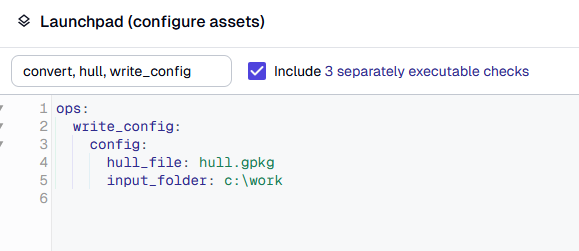
My solution is to have a separate asset that reads the configuration from MyAssetConfig and stores it as a JSON file. This file is then read by all downstream assets. This means that I only need to set the parameters once. Unfortunately, it’s still not possible to get persistent configuration storage this way – the only way I see to do this is by writing a Python file and reloading the asset definition. As it is now, the launchpad values will always revert to the default values defined in the Python code. My solution for now is to have a separate job definition that omits writing the configuration, meaning that the last used configuration will be read from the JSON file.
Further steps and conclusions
This touches just the surface, but is enough for manually running pipelines. Dagster does of course offer functionality for automating runs, such as at a given time interval or triggered by an event. At some point you might also want to leave the development environment and move to production. The documentation explains all of these steps, and you can join the Dagster Slack community if you want to ask questions.
Despite seeing some room for improvement, I’m quite happy with Dagster and have started implementing a few of my processing pipelines in it. I like how little code is required to define a pipeline. Using Python code, it is a natural fit for data science and machine learning workflows. Command line tools written in other languages can of course be executed via os.system() calls.



{kind=link}
{kind=link}
{kind=link}
{kind=link}